API for 500 sensors
Highly available & scalable solution for sensors.
SYSTEM DESIGN
Mirza Usman Tahir
2/27/20242 min read
Problem Statement:
In a constrained environment, there are around 500 sensors that are sending around 4 requests per second to your web server. Each request has a unique id in the payload for identification. Sometimes, the sensors misfire and send the same request multiple times as well and in this case only one request should be catered.
Design a system for this environment so that your service can handle these 2000 requests per second with 100% availability. The data being sent from the server needs to be eventually saved in a database and the solution should be horizontally scalable.
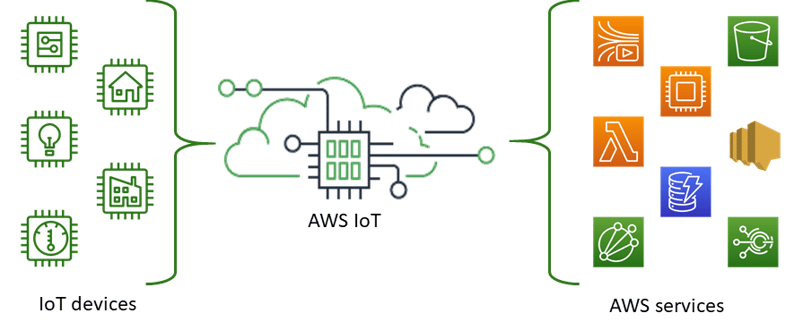
Proposed Solution:
Let’s design a system that handles high-throughput data from 500 sensors, ensures fail-safe ingestion, and deduplicates requests with unique IDs. We’ll use AWS IoT, Lambda functions, and DynamoDB majorly to achieve this.
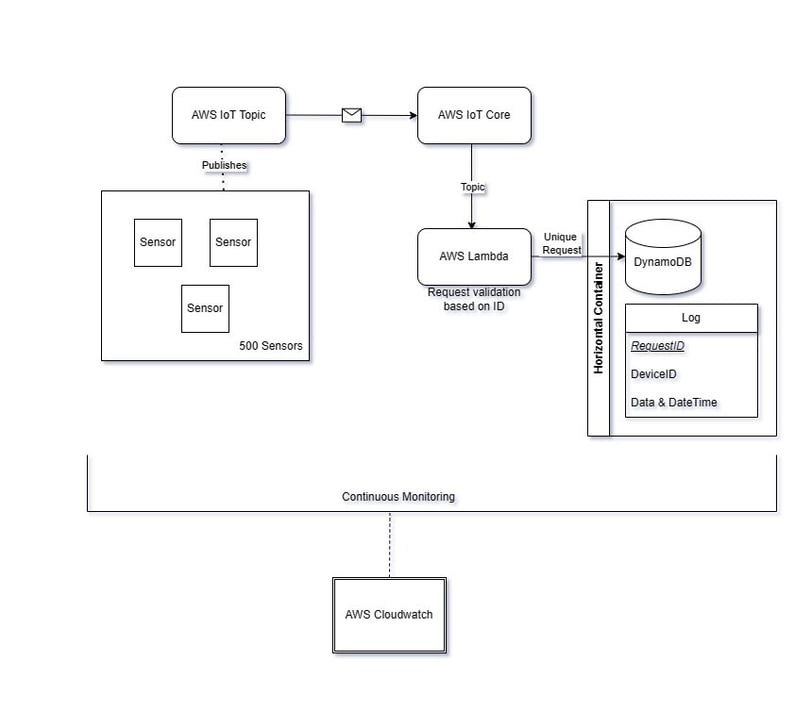
The architecture details are as follows,
IoT Devices (Sensors):
These 500 sensors generate log data (requests) and publish messages to an AWS IoT Topic.
Each request includes a unique ID for identification.
IoT Topics can be divided based on sensor type. So if all sensors are of same nature(tempreture sensors) all of them will be posting details to same IoT Topic. This way it supports adding new sensors in the system as well.
AWS IoT Core:
IoT Core receives messages from sensors via MQTT or HTTP(REST API) protocol.
It ensures secure communication and authentication.
IoT Core routes messages to the appropriate topic.
IoT Topic Rule:
An AWS IoT Topic Rule subscribes to the IoT topic where sensors publish data.
The rule triggers an AWS Lambda function when new messages arrives.
The Lambda function processes incoming requests.
AWS Lambda Function:
The Lambda function:
Validates the request payload.
Checks if the request ID is unique.
If the ID is unique, it stores the request data in Amazon DynamoDB.
If the ID is a duplicate, it ignores the request.
A Redis instance can optionally be paired up to speed up the request ID validation.
Amazon DynamoDB:
DynamoDB stores the processed data (unique requests).
DynamoDB table can have the request ID as the primary key, device ID column and the sensor data.
DynamoDB makes horizontal database scaling possible.
Error Handling and Retries:
Amazon CloudWatch can be utilized to keep an eye on logs.
Will need to continuously monitor DynamoDB metrics and alarms.
AWS services scale automatically based on workload. Besides that we need to continuously monitor performance, and set up alarms to ensure the reliability and efficiency of the system.
[Architecture Diagram]
Contacts
mirzausman501@gmail.com
Subscribe to my newsletter
+923315423062